【论文随笔】SAC
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor ICML 2018
Idea
Model-free methods typically suffer from very high sample complexity and brittle convergence properties. SAC is an off-policy maximum entropy, stochastic actor-critic algorithm that encourages exploration and provides for both sample efficiency and learning stability.
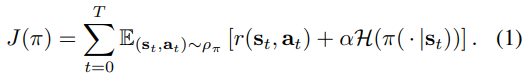
Theory
Present a convergence proof for policy iteration (policy evaluation and policy improvement) in the maximum entropy framework.
Algo
An actor-critic framework consist of target and current soft value networks $V_{\psi}\left(s_{t}\right)$ and $V_{\bar{\psi}}\left(s_{t}\right)$ , double Q value networks $Q_{\theta_{1,2}}\left(s_{t},a_{t}\right)$ and an actor network $\pi_{\phi}\left(a_{t}\mid s_{t}\right)$.

Env & Baselines
Gym, Humanoid(rllab) [continuous tasks]
DDPG, PPO, SQL, TD3, Trust-PCL
Exp
- Comparative Evaluation with DDPG, PPO, SQL, TD3(Gym, Humanoid rllab)
- Ablation Study
- Stochastic vs deterministic policy (remove entropy) [Humanoid rllab] $\to$ Stochasticity can stabilize training.
- Policy evaluation [Gym Ant-v1] $\to$ Deterministic evaluation can yield better performance.
- Reward scale hyperparameter [Gym Ant-v1] $\to$ With the right reward scaling, the model balances exploration and exploitation, leading to faster learning and better asymptotic performance.
- Target network update [Gym Ant-v1] $\to$ Large $\tau$ can lead to instabilities while small $\tau$ can make training slower.